洋面散射计资料的处理¶
转换成 LITTLE_R 格式¶
下载观测资料
运行
little_r_usage_v02.1.py程序:例如:下载了
20191028的观测资料为:ascat_20191028_v02.1.gzpython ./little_r_usage_v02.1.py -d 20191028 > obs.20191028.little_robs.20191028.little_r包括了20191028全天的观测资料;除了产生little_r格式的文件obs.20191028.little_r外,同时产生两个图形文件:20191028_0.png和20191028_1.png,分别为上行和下行轨道的观测。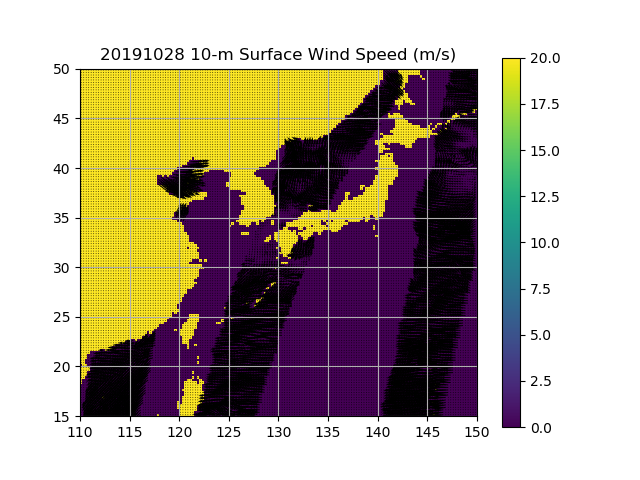
20191028_0.png
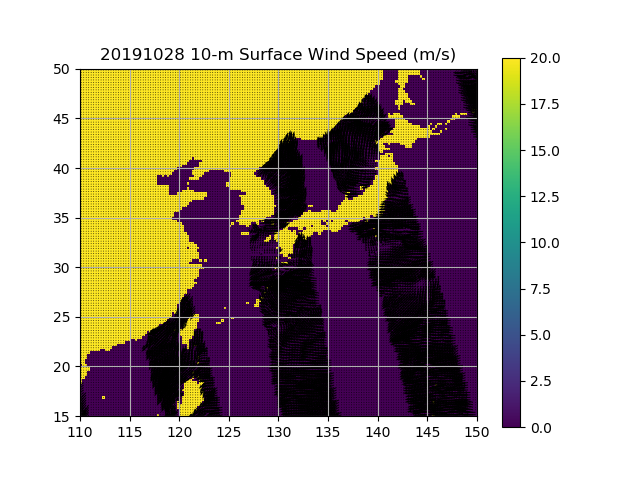
20191028_1.png
主程序
little_r_usage_v02.1.pyfrom ascat_daily import ASCATDaily import fortranformat as ff import numpy as np def read_data(filename): dataset = ASCATDaily(filename, missing=missing) if not dataset.variables: sys.exit('file not found') return dataset lons = (117,127) lats = (34,41) lons = (110,150) lats = (15,50) iasc = 1 wspdname = 'windspd' wdirname = 'winddir' missing = -999. rpt_format = ff.FortranRecordWriter ('( 2f20.5, 2a40, 2a40, 1f20.5, 5i10, 3L10, 2i10, a20, 13( f13.5 , i7 ) ) ') mesa_format = ff.FortranRecordWriter ('( 10( f13.5 , i7 ) )') end_format = ff.FortranRecordWriter (' ( 3 ( i7 ) ) ') lr_missing = -888888 lr_end_data = -777777.0 lr_missing_r = lr_missing platform = "FM-281 QSCAT " def myvmax(): return 20 def myscale(): return 320 def mycolor(): return 'black' def little_r(date, ds): # get lon/lat: lon = dataset.variables['longitude'] lat = dataset.variables['latitude'] counter = 1 for iasc in (0, 1): # here is the data I will use: wspd = dataset.variables[wspdname][iasc,:,:] wdir = dataset.variables[wdirname][iasc,:,:] mins = dataset.variables['mingmt'][iasc,:,:] for j in range(len(lon)): for i in range(len(lat)): if ( wdir[i,j] < 0 and mins[i,j] > 1440 ) : continue if (lat[i] < lats[0] or lat[i] > lats[1] or lon[j] < lons[0] or lon[j] > lons[1] ) : continue offset_h, offset_m = divmod(mins[i,j], 60) datetime = date + str(int(offset_h)).zfill(2) + str(int(offset_m)).zfill(2) + '00' print(rpt_format.write([lat[i] , lon[j] , "" , "" , platform , 'http://data.remss.com/ascat' , 0. , 6 , 0 , 0 , counter , 0 , False , False , False , lr_missing , lr_missing , datetime , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0])) print(mesa_format.write([lr_missing_r , 0 , 0. , 0 , lr_missing_r , 0 , lr_missing_r , 0 , wspd[i,j] , 0 , wdir[i,j] , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 ])) print(mesa_format.write([lr_end_data , 0 , lr_end_data , 0 , 1., 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0 , lr_missing_r , 0])) print(end_format.write([1, 0, 0])) counter = counter + 1 #---------------------------------------------------------------------------- def show_dimensions(ds): print('') print('Dimensions') for dim in ds.dimensions: aline = ' '.join([' '*3, dim, ':', str(ds.dimensions[dim])]) print(aline) def show_variables(ds): print('') print('Variables:') for var in ds.variables: aline = ' '.join([' '*3, var, ':', ds.variables[var].long_name]) print(aline) def show_validrange(ds): print('') print('Valid min and max and units:') for var in ds.variables: aline = ' '.join([' '*3, var, ':', str(ds.variables[var].valid_min), 'to', str(ds.variables[var].valid_max), '(',ds.variables[var].units,')']) print(aline) def set_image(vmin,vmax,extent): myimage = {} myimage['origin'] = 'lower' myimage['vmin'] = vmin myimage['vmax'] = vmax myimage['extent'] = extent myimage['interpolation'] = 'nearest' return myimage def quikquiv(plt,lon,lat,u,v,scale,region,color): # selecting the sub-region is not necessary, # but it greatly reduces time needed to render plot ilon1,ilon2,ilat1,ilat2 = region xx = lon[ilon1:ilon2+1] yy = lat[ilat1:ilat2+1] uu = u[ilat1:ilat2+1,ilon1:ilon2+1] vv = v[ilat1:ilat2+1,ilon1:ilon2+1] plt.quiver(xx,yy,uu,vv,scale=scale,color=color) def show_plotexample(date, dataset, iasc): #print('') #print('Plot example:') figname = date + '_' + str(iasc) + '.png' # modules needed for this example: import pylab as plt from matplotlib import cm # here is the data I will use: wspd = dataset.variables[wspdname][iasc,:,:] wdir = dataset.variables[wdirname][iasc,:,:] land = dataset.variables['land'][iasc,:,:] # get lon/lat: lon = dataset.variables['longitude'] lat = dataset.variables['latitude'] # get metadata: name = dataset.variables[wspdname].long_name units = dataset.variables[wspdname].units vmin = dataset.variables[wspdname].valid_min vmax = dataset.variables[wspdname].valid_max # get extent of dataset: extent = [] extent.append(dataset.variables['longitude'].valid_min) extent.append(dataset.variables['longitude'].valid_max) extent.append(dataset.variables['latitude'].valid_min) extent.append(dataset.variables['latitude'].valid_max) # get region to plot: ilon1 = np.argmin(np.abs(lons[0]-lon)) ilon2 = np.argmin(np.abs(lons[1]-lon)) ilat1 = np.argmin(np.abs(lats[0]-lat)) ilat2 = np.argmin(np.abs(lats[1]-lat)) region = (ilon1,ilon2,ilat1,ilat2) # get u and v from wspd and wdir: from bytemaps import get_uv u,v = get_uv(wspd,wdir) bad = np.where(wspd<0) u[bad] = 0. v[bad] = 0. # set colors: palette = cm.jet palette.set_under('black') palette.set_over('grey') wspd[land] = 1.E30 # my preferences: vmax = myvmax() scale = myscale() color = mycolor() # make the plot: fig = plt.figure() plt.imshow(wspd,**set_image(vmin,vmax,extent)) plt.colorbar() plt.xlim(lons) plt.ylim(lats) quikquiv(plt,lon,lat,u,v,scale,region,color) plt.title(date + ' ' + name+' ('+units+')') plt.grid() fig.savefig(figname) #print(' '.join([' '*3,'Saving:',figname])) #---------------------------------------------------------------------------- if __name__ == '__main__': import sys import datetime import argparse parser = argparse.ArgumentParser(description='Example of usage') parser.add_argument('-d', '--date', dest='start_date', default=None, required=True, help='date in format "YYYYMMDD"') args = parser.parse_args() start_date_object = args.start_date filename = 'ascat_' + start_date_object + '_v02.1.gz' dataset = read_data(filename) #show_dimensions(dataset) #show_variables(dataset) #show_validrange(dataset) show_plotexample(start_date_object, dataset, 0) show_plotexample(start_date_object, dataset, 1) little_r(start_date_object, dataset) #print('') #print('done') #print('')
模块
bytemaps.py""" Module for reading and verifying RSS gridded binary data files. """ import copy import decimal import gzip import numpy as np import sys from collections import namedtuple from collections import OrderedDict from operator import mul from functools import reduce class Dataset: """ Base class for bytemap datasets. """ """ Public data: filename = name of data file missing = fill value used for missing data; if None, then fill with byte codes (251-255) dimensions = dictionary of dimensions for each coordinate variables = dictionary of data for each variable All classes derived from Dataset must implement the following: _attributes() = returns list of attributes for each variable (list) _coordinates() = returns coordinates (tuple) _shape() = returns shape of raw data (tuple) _variables() = returns list of all variables to get (list) The derived class must provide "_get_" methods for the attributes. If the derived class provides "_get_" methods for the variables, those methods receive first priority. The "_get_" methods in this module receive second priority. The last priority is "_default_get", which requires: _get_index(var) = returns bmap index for var _get_scale(var) = returns bmap scale for var _get_offset(var) = returns bmap offset for var """ def __init__(self): self.dimensions = self._get_dimensions() self.variables = self._get_variables() def _default_get(self,var,bmap): data = get_data(bmap,self._get_index(var)) acopy = copy.deepcopy(data) bad = is_bad(data) try: data *= self._get_scale(var) except _NoValueFound: pass try: data += self._get_offset(var) except _NoValueFound: pass if self.missing == None: data[bad] = acopy[bad] else: data[bad] = self.missing return data def _dtype(self): return np.uint8 def _get(self,var): try: return _get_(var,_from_=self) except _NoMethodFound: pass try: return _get_(var,_from_=thismodule()) except _NoMethodFound: pass return self._default_get def _get_avariable(self,var,data): variable = self._get(var)(var,data) return Variable(var,variable,self) def _get_coordinates(self,var=None): if not var: return self._coordinates() if var in self._coordinates(): return (var,) return tuple([c for c in self._coordinates() if c != 'variable']) def _get_dimensions(self): dims = OrderedDict(zip(self._coordinates(),self._shape())) del dims['variable'] return dims def _get_variables(self): data = OrderedDict() try: stream = readgz(self.filename) except: return data bmap = unpack(stream, shape=self._shape(), dtype=self._dtype()) for var in self._variables(): data[var] = self._get_avariable(var,bmap) return data def readgz(filename): f = gzip.open(filename,'rb') stream = f.read() f.close() return stream def thismodule(): return sys.modules[__name__] def unpack(stream,shape,dtype): count = reduce(mul,shape) return np.fromstring(stream,dtype=dtype,count=count).reshape(shape) """ Library of Methods for _get_ Functions: """ def btest(ival,ipos): """Same usage as Fortran btest function.""" return ( ival & (1 << ipos) ) != 0 def cosd(x): return np.cos(np.radians(x)) def get_data(bmap,indx,dtype=np.float64): """Return numpy array of dytpe for variable in bmap given by indx.""" return np.array(np.squeeze(bmap[...,indx,:,:]),dtype=dtype) def get_uv(speed,direction): """ Given speed and direction (degrees oceanographic), return u (zonal) and v (meridional) components. """ u = speed * sind(direction) v = speed * cosd(direction) return u, v def ibits(ival,ipos,ilen): """Same usage as Fortran ibits function.""" ones = ((1 << ilen)-1) return ( ival & (ones << ipos) ) >> ipos def is_bad(bmap,maxvalid=250): """Return mask where data are bad.""" return bmap > maxvalid def sind(x): return np.sin(np.radians(x)) where = np.where """ Library of Named Exceptions: """ _NoMethodFound = AttributeError _NoValueFound = (AttributeError,KeyError) _NotFound = AttributeError """ Library of Named _get_ Functions: """ def _get_(var,_from_): return getattr(_from_,'_get_'+var) def _get_ice(var,bmap,indx=0,icevalue=252): return get_data(bmap,indx,dtype=bmap.dtype) == icevalue def _get_land(var,bmap,indx=0,landvalue=255): return get_data(bmap,indx,dtype=bmap.dtype) == landvalue def _get_latitude(var,bmap,nlat=720,dlat=0.25,lat0=-89.875): if np.shape(bmap)[-2] != nlat: sys.exit('Latitude mismatch') return np.array([dlat*ilat + lat0 for ilat in range(nlat)]) def _get_longitude(var,bmap,nlon=1440,dlon=0.25,lon0=0.125): if np.shape(bmap)[-1] != nlon: sys.exit('Longitude mismatch') return np.array([dlon*ilon + lon0 for ilon in range(nlon)]) def _get_nodata(var,bmap,indx=0): return is_bad(get_data(bmap,indx,dtype=bmap.dtype)) class Variable(np.ndarray): """ Variable exists solely to subclass numpy array with attributes. """ def __new__(cls,var,data,dataset): obj = np.asarray(data).view(cls) for attr in dataset._attributes(): get = _get_(attr,_from_=dataset) setattr(obj,attr,get(var)) return obj class Verify: """ Base class for bytemap read verification. """ """ Public data: data = OrderedDict of OneOb-namedtuple lists for each variable success = True/False The derived class must supply the following: For all files: filename = name of verify file variables = list of variables to verify The following indices (1-based): ilon1 = longitude index ilon2 = longitude index ilat1 = latitude index ilat2 = latitude index iasc = asc/dsc index (daily only) For files organized as a list: startline = starting line number of data (integer) columns = column numbers for each variable (dictionary) For files organized as arrays: startline = starting line number of data for each variable (dict) The startline and columns are counting starting from 1. """ def __init__(self,dataset): self._file = [tokenize(line) for line in readtext(self.filename)] self.data = self._get_data() self.success = verify(dataset,self) def _asc(self): try: return zerobased(self.iasc) except _NotFound: return Ellipsis def _get_avariable(self,var): data = [] indices = np.ndindex(self._nlat(),self._nlon()) for ilat,ilon in indices: data.append(self._get_oneob(var,ilon,ilat)) return data def _get_data(self): data = OrderedDict() for var in self.variables: data[var] = self._get_avariable(var) return data def _get_line_word(self,var,ilon,ilat): if self._islist(): return self._get_line_word_list(var,ilon,ilat) else: return self._get_line_word_array(var,ilon,ilat) def _get_line_word_array(self,var,ilon,ilat): iline = zerobased(self.startline[var]) + ilat iword = ilon return iline,iword def _get_line_word_list(self,var,ilon,ilat): iline = zerobased(self.startline) + ilat*self._nlon() + ilon iword = zerobased(self.columns[var]) return iline,iword def _get_oneob(self,var,ilon,ilat): iline,iword = self._get_line_word(var,ilon,ilat) avalue = self._file[iline][iword] return OneOb(self._lon(ilon), self._lat(ilat), self._asc(), float(avalue), places(avalue)) def _islist(self): return hasattr(self,'columns') def _lat(self,ilat): return zerobased(self.ilat1) + ilat def _lon(self,ilon): return zerobased(self.ilon1) + ilon def _nlat(self): return self.ilat2 - self.ilat1 + 1 def _nlon(self): return self.ilon2 - self.ilon1 + 1 OneOb = namedtuple('OneOb','lon lat asc val ndp') """ OneOb corresponds to one observation from verify file with: lon = longitude index lat = latitude index asc = ascending/descending index val = verify value ndp = number of decimal places given in verify The (asc,lat,lon) indices are 0-based. """ def places(astring): """ Given a string representing a floating-point number, return number of decimal places of precision (note: is negative). """ return decimal.Decimal(astring).as_tuple().exponent def readtext(filename): f = open(filename,'r') lines = f.readlines() f.close() return lines def tokenize(line): return [item.strip() for item in line.split()] def verify(dataset,verify): """ Verify data were read correctly. """ """ Required arguments: dataset = a read Dataset instance verify = a Verify instance Returns: success = True or False """ success = True for var in verify.variables: for ob in verify.data[var]: readval = dataset.variables[var][ob.asc, ob.lat, ob.lon] diff = abs(ob.val - readval) match = diff < pow(10,ob.ndp) if not match: success = False print( ' '.join([str(ob.lon), str(ob.lat), str(var), str(ob.val), str(readval), str(diff), str(match)]) ) return success def zerobased(indx): return indx-1 if __name__ == '__main__': link = 'http://www.remss.com/terms_of_data_use/terms_of_data_use.html' print('Remote Sensing Systems') print('444 Tenth Street, Suite 200') print('Santa Rosa, CA 95401, USA') print('FTP: ftp://ftp.ssmi.com') print('Web: http://www.remss.com') print('Support: support@remss.com') print('Terms of Data Use: '+link)